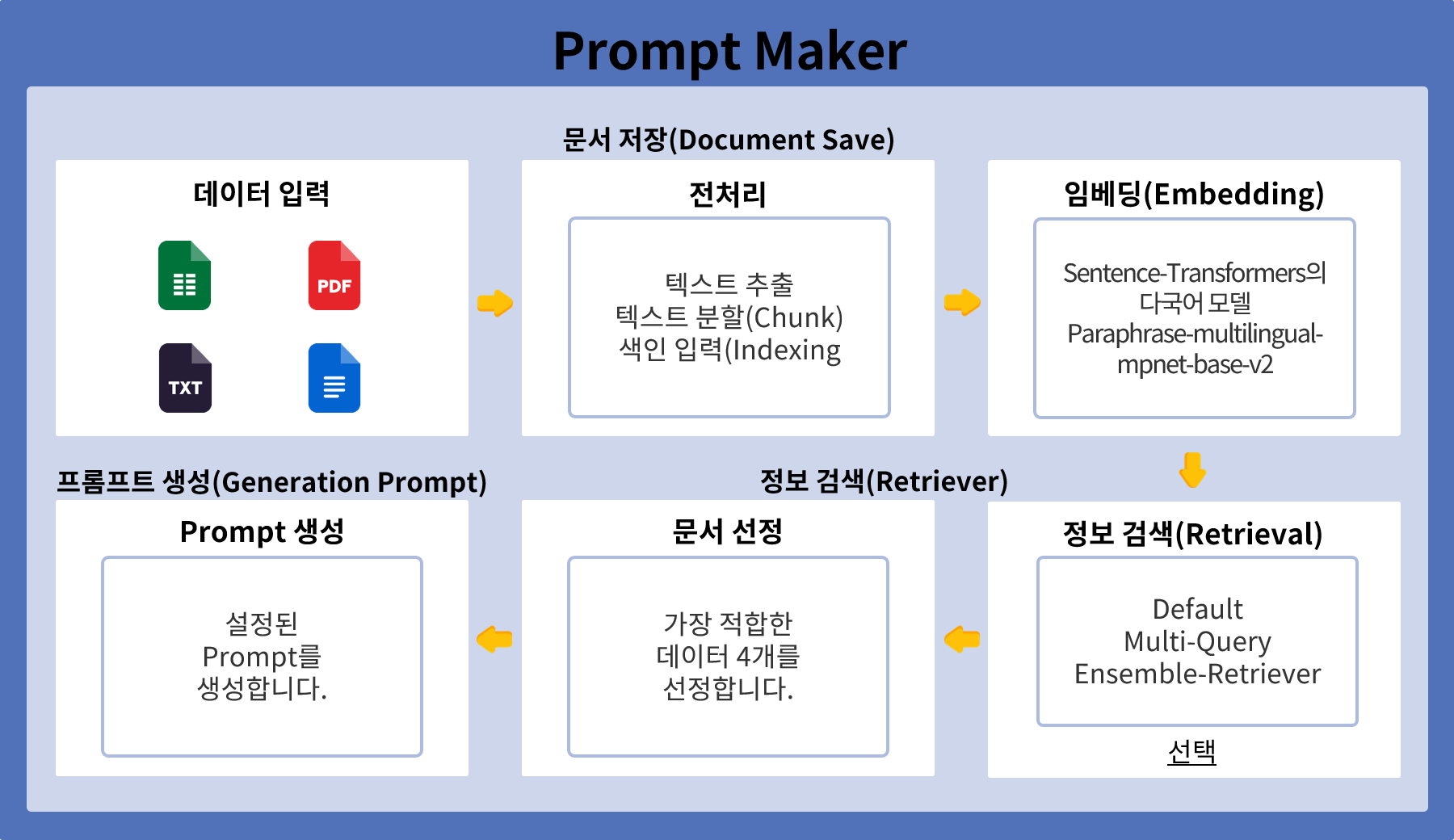
문서 저장
(Document Save)
앙상블 검색기를 구성하는 ChromaDB와 멀티쿼리 방식은 두개 모두 다른 방식으로 저장하는게 아니라 같은 입력 데이터를 바탕으로 같은곳에 저장된 벡터화 데이터를 가지고 검색을 진행합니다 또한 BWSE의 경우는 독자적인 저장소에 벡터화한 데이터를 저장합니다.


질문 처리
(Input Query Processing)
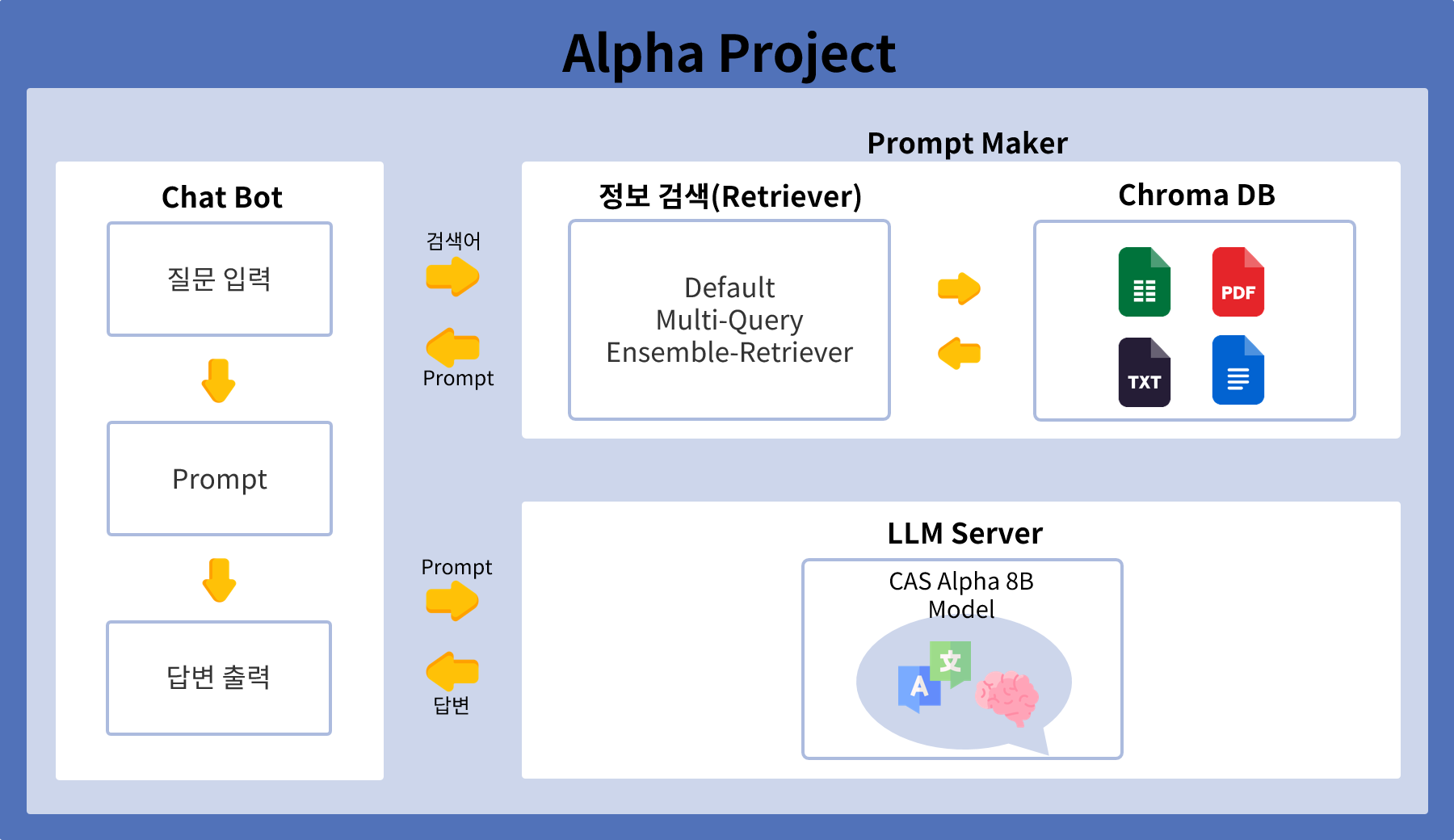
Prompt Maker의 앙상블 검색기는 사용자 질문 처리를 통해 검색 쿼리를 벡터화하여 진행됩니다. 사용자가 특정 정보를 요청하면, 입력된 쿼리는 전처리 과정을 거쳐 벡터화됩니다. 이 벡터화된 쿼리는 앙상블 검색기를 구성하는 VectorDB와 BWSE 동시에 입력됩니다. VectorDB는 유사 질문을 검색하여 관련 자료를 찾고, Chromadb와 BWSE는 쿼리와 직접적으로 관련된 자료를 검색합니다. 두 데이터베이스에서 나온 결과는 각각 가중치를 부여받아 통합됩니다. 최종적으로 가중치가 높은 결과를 우선으로 하여 최적의 프롬프트를 구성해 사용자의 질문에 대한 답변을 제공합니다.


정보 검색
(Retrieval)
Prompt Maker의 정보 검색(Retrieval) 과정은 ChromaDB와 BWSE그리고 멀티쿼리 각각의 프로세스를 통해 각각의 데이터를 검색한 후, 가중치를 부여하여 최종 Prompt를 구성하는 방식입니다. 사용자가 특정 정보를 요청하면, 벡터화된 쿼리가 ChromaDB와 BWSE 그리고 멀티쿼리 프로세스에 동시에 입력됩니다. ChromaDB는 쿼리와 직접적으로 관련된 자료를 검색하고, 멀티쿼리는 유사한 질문들을 검색하여 관련 자료를 찾습니다. 각각의 데이터베이스에서 나온 결과는 각각 가중치를 부여받아 통합됩니다. 이러한 가중치는 검색 쿼리와의 유사도, 자료의 신뢰성 등을 기반으로 결정됩니다. 가중치가 부여된 데이터 목록은 Reference에 비율을 설정하여 추가되고, 이를 통해 최적의 Prompt를 구성하여 사용자의 질문에 대한 답변을 제공합니다.